

Frequently Asked Questions
Data Basics
Q: What are MODIS Data "Collections"?
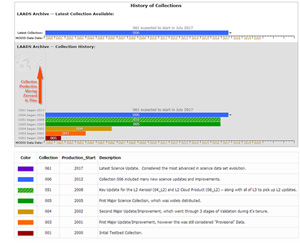 A: A MODIS data "Collection" is basically a MODIS data version. When new & improved science algorithms are developed, the entire MODIS dataset (from launch) is reprocessed and then tagged & distributed as a new "Collection". During the processing of a Collection, an attempt is made to use the same version of the Science Algorithms or Program Executables (PGEs). However, sometimes a bug is found in one or more of the PGEs in the middle of Collection processing; and if the bug is not serious, processing will complete with the new corrected PGE. These anomalies and problems in processing are noted on the Data Issues page (The example page here is for Clouds).. One can always identify the Collection number for a particular HDF file as it's always included (as a 3 digit number) as part of the HDF filename. There have been seven MODIS data Collections (or Versions) processed since MODIS/Terra was launched in early 2000. The Collection versions created thus far are 001, 003, 004, 005, 051, 006, and 061. It should be noted that Collections ending in 1 (e.g. 051 and 061) only contain updates for some MODIS Data Products, since it was considered an incremental update of the Collection 005 and Collection 006, respectively. As of Summer of 2017, Collection 006 was the latest fully completed collection. Finally, changes and testing for the next Collection (061) are completed. Processing and availability of Collection 061 data is slated to begin in July 2017. Documentation has been generated that outline the changes and improvements offered in each Collection in the Documentation section of this website.
A: A MODIS data "Collection" is basically a MODIS data version. When new & improved science algorithms are developed, the entire MODIS dataset (from launch) is reprocessed and then tagged & distributed as a new "Collection". During the processing of a Collection, an attempt is made to use the same version of the Science Algorithms or Program Executables (PGEs). However, sometimes a bug is found in one or more of the PGEs in the middle of Collection processing; and if the bug is not serious, processing will complete with the new corrected PGE. These anomalies and problems in processing are noted on the Data Issues page (The example page here is for Clouds).. One can always identify the Collection number for a particular HDF file as it's always included (as a 3 digit number) as part of the HDF filename. There have been seven MODIS data Collections (or Versions) processed since MODIS/Terra was launched in early 2000. The Collection versions created thus far are 001, 003, 004, 005, 051, 006, and 061. It should be noted that Collections ending in 1 (e.g. 051 and 061) only contain updates for some MODIS Data Products, since it was considered an incremental update of the Collection 005 and Collection 006, respectively. As of Summer of 2017, Collection 006 was the latest fully completed collection. Finally, changes and testing for the next Collection (061) are completed. Processing and availability of Collection 061 data is slated to begin in July 2017. Documentation has been generated that outline the changes and improvements offered in each Collection in the Documentation section of this website.
The following link shows a summary overview of all the MODIS Atmosphere Collections processed thus far:
The links below provides more detail on the changes made in the latest processed Collections:
Collection 006 Change Summary
Collection 061 Change Summary
Tracking Algorithm Changes and Data Issues
Q: How can I track incremental iterations of MODIS Data (Algorithm Updates)?
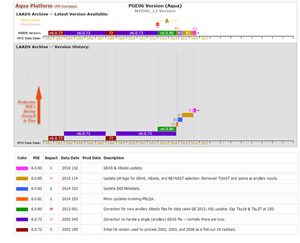 A: A MODIS Data Processing & Availability Calendar is available that shows the latest Program Executable (PGE) Version for each MODIS Data Product on a month by month basis. As of July 2017, Collection 006 is the last fully completed collection and Collection 061 is slated to begin. This start of Collection 061 will be noted by new C061 PGE Versions in these tables and graphs.
A: A MODIS Data Processing & Availability Calendar is available that shows the latest Program Executable (PGE) Version for each MODIS Data Product on a month by month basis. As of July 2017, Collection 006 is the last fully completed collection and Collection 061 is slated to begin. This start of Collection 061 will be noted by new C061 PGE Versions in these tables and graphs.
It should be noted that the MODIS data record began in March 2000 for Terra (Terra is the AM platform with a 10:30 LST nomimal daytime overpass) and July 2002 for Aqua (Aqua is the PM platform with a 13:30 LST nominal daytime overpass). Finally, note that MODIS Terra HDF files always begin with the prefix "MOD", while MODIS Aqua HDF files always begin with the prefix "MYD".
Q. How can I track data issues and bug fixes in MODIS Data?
A. A comprehensive Data Issues section is available on this website. Tracking of data issues, known problems, and subsequent fixes is an important issue for MODIS data users. This Data Issues section of the website will act as a repository of all known MODIS Atmosphere Data Product problems and issues, as well as how to determine the problematic version (and the fixed version, if available) of the HDF data. Therefore data users should stay apprised of updates to this section. Data Users unfamiliar with how to properly track problems and fixes by determining the version of their downloaded HDF files should refer to the documentation provided in this section.
Data Issues (Example of the Cloud Product Data Issues page, see LHS links for other products)
Ordering Data
Q: How do I order MODIS Data?
A: MODIS Data is distributed free of charge through the Level 1 and Atmosphere Archive and Distribution System (LAADS). By utilizing the Search & Order Tool on the LAADS web site, one can search and subset data by collection, date & time, geographic area, science products, and selected metadata.
Instructions on the FTP site: After you load the FTP page -- click on directory "6" for Collection 6 (006) data -- click on directory "61" for Collection 6.1 (061) data. The FTP directories that start with "MOD" are for Terra MODIS HDF data; the directories that start with "MYD" are for Aqua MODIS HDF data. The FTP directories that start with "MOB" or "MYB" contain Terra or Aqua browse images.
LAADS WEB Search and Order Site
LAADS FTP Download Site
Q: What is the best way to obtain a time-series of point data from a MODIS L2 product? For example: a time series of data for Sherbrooke, Canada. If I download the L2 granules, there will be a large number of files and it will take a lot of time to process and extract the point data.
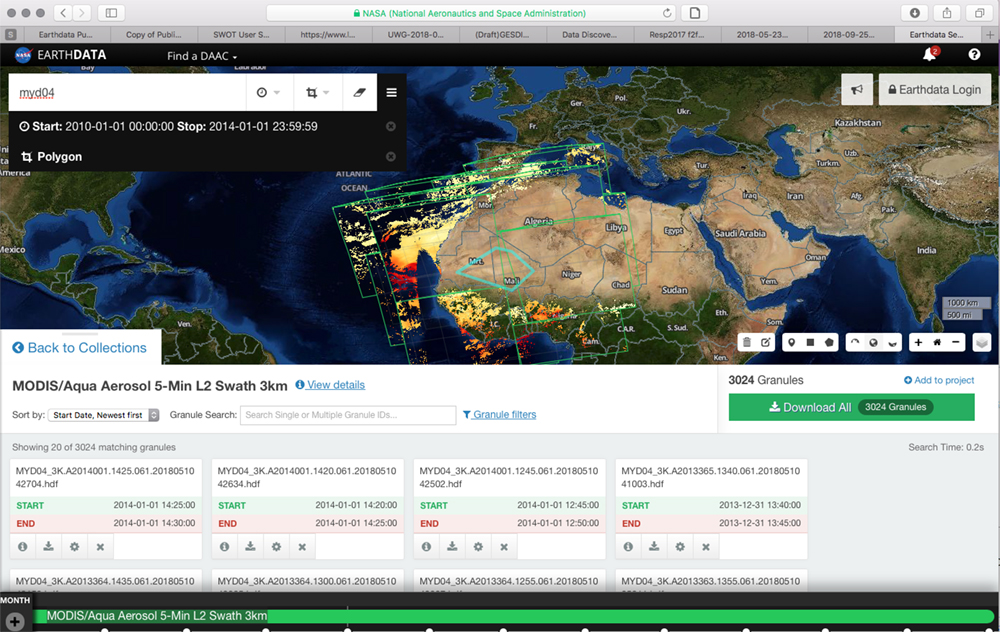
A: First, one can get these L2 (or L3) files from the LAADS data server (https://ladsweb.modaps.eosdis.nasa.gov). This server also lets you search to find granules covering your location of interest. When you order data make sure you get the latest Collection data. In general, it is always better to get data directly from LAADS as opposed to a secondary archive. To overcome large number of files, LAADS provides several options of post processing while ordering data, this includes sub setting for smaller area, selection of SDS and even creating time-series of files. If you are trying to cover a lot of stations, you may have to pull all the L2 files, then sift through them locally. If you only need to cover a few geographical points, you can identify the granules you need from the “geoMeta” daily files (https://ladsweb.modaps.eosdis.nasa.gov/) -- then, pull only the file(s) that cover the area of interest. It’s fairly straight-forward to extract data from those files inside a box of interest. Here are sample spreadsheets done with 10 km Aqua data where the box of interest is the continental US (CONUS) (https://modis-images.gsfc.nasa.gov/ftpwww/private/conus_aod_combined/aq…).
Jennifer Wei (GSFC-6102) <jennifer.c.wei@nasa.gov>, a part of the Giovanni Team, also offered this in response to this question: What kind of subsetting (bounding box, point, or shapefile)? Do they need data transformation (from hdf to nc or GeoTiff)? Do they need to extract the variable from the file? Overall, they can use Earthdata Search client (https://search.earthdata.nasa.gov/). Attached the screenshot that I used for MYD04 inside a polygon for 2010-01-01 to 2014-01-01. The query can be seen at the following link (https://search.earthdata.nasa.gov/search/granules?polygon=-5.34375%2C22.78125%2C-12.9375%2C18%2C-2.25%2C14.484375%2C1.96875%2C18.28125%2C-2.25%2C22.078125%2C-5.34375%2C22.78125&p=C1443528505-LAADS&m=3.65625!-4.921875!2!1!0!0%2C2&tl=1520260284!4!!&qt=2010-01-01T00%3A00%3A00.000Z%2C2014-01-01T23%3A59%3A59.000Z&q=myd04&ok=myd04)
Analyzing Data
Q: How do I read, interpret, or visualize MODIS Data?
A: MODIS Data is stored in Heirarchical Data Format (HDF). There are a number of tools and programs already written to read and visualize MODIS data. These include GUI, web-based, and command line programs that are written in IDL, FORTRAN, and C. Many of these are distributed in our TOOLS section:
MODIS Data Tools (for reading & visualizing)
Users that wish to unpack Level-2 (L2) Orbital Granule MODIS data (at 1km, 5km, 10km resolution) are advised to become familiar with the MODIS QA Plan; which details how to read, as well as the content of the Level-2 QA arrays. These QA arrays contain bit-flags that detail input data source, processing path, quality, as well as detailed characteristics and properties of Level-2 retrievals. Also available on the page linked below are Algorithm Theoretical Basis Documents (ATBDs) for MODIS Data Products. These ATBDs provide the scientific background of MODIS data.
Users working with Level-3 (L3) Daily, Eight-day, or Monthly Global Gridded MODIS data (at 1 degree resolution) are advised to become familiar with the Level-3 Algorithm Theoretical Basis Document. This document details characteristics, properties, and content of Level-3 data. Also included in this document are user caveats and frequently asked questions. The L3 ATBD is linked on the above 'QA Plan & ATBDs' page, as well as individual 'Theoretical Basis' pages in the L3 product sections. The link for the 'Theoretical Basis' page in the L3 Monthly product section is provided below. It should be noted that there is only one L3 ATBD for all L3 products (Daily, Eight-day, & Monthly).
L2 & L3 ATBDs, Plans, and Guides
Q: Many retrieval parameters are stored as integers in the HDF file. How do I convert these to something useful?
A: HDF files are self describing, so local attributes are attached to each and every Scientific Data Set (SDS). These local attributes contain information such as valid_range, scale_factor, add_offset. Nearly all MOD06 retrieval parameters are stored as 16-bit integers to reduce the HDF file size. To convert these back to useful floating point values, one must first read the scale_factor and add_offset local attributes of each SDS. The conversion equation then follows the HDF standard:
float_value = scale_factor * (integer_value – add_offset)
It is interesting to note that the add_offset local attribute is subtracted from (not added to) the stored integer. That is because the notation is reflective of how the data was packed (from the programmers perspective) rather than unpacked (from the data users perspective).
Q: How do I read and/or interpret bit flag SDS's in Level-2 (L2) MODIS Products?
A. Most MODIS Atmosphere HDF data products contain one or more "bit flag" Scientific Data Set (SDS) arrays. Bit flag SDS names may contain the string "Quality_Assurance" or may have a more descriptive name like "Cloud_Mask". However, they all have one common attribute - bit flag arrays contain multiple flags stored in particular (fixed) bit positions of the array.
All of the bit flag arrays in MODIS Atmosphere HDF data products are described more completely in the QA Plan.
It should be noted that for MODIS Atmosphere products, the term QA (short for Quality Assurance) is loosely defined to include a wide variety of flags that detail 1.) Confidence or Quality , 2.) Processing Path, 3.) Status or Outcome, 4.) Retrieval Method, 5.) Data or Scene Characteristics, and 6.) Metadata or Ancillary Input Source.
The convention for indexing arrays varies from language to language. Array indexing in FORTRAN typically starts at 1; and array indexing in C typically starts at 0. However, almost all tools used for bit extraction (in both FORTRAN and C) use an index start convention of 0 for both bits and bytes. In addition, the HDF interface is based in the C (0-based) language. Therefore a 0-based start convention for indexing (numbering) the bits and bytes is used here.
Qualities of HDF data for bits and bytes:
-
Bit and Byte Array Indexing Convention: "Zero-based"
-
Bit and Byte Array Ordering Convention: "Big-Endian"
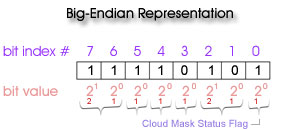
Bit-String Dumps
If you use a tool that dumps bit registers (01001001), you need to keep in mind that standard HDF data products (including all MODIS HDF data) are written using the big-endian referencing scheme. Since HDF is platform-independent, the HDF library will perform no byte-order conversion on big-endian platforms; if the platform being used is little-endian, the library will convert the byte-order of the variables to big-endian. Therefore, when "stripping bits" from a Bit String SDS's (Quality Assurance or Cloud Mask arrays, for example) using bit manipulation tools, the bits will always be numbered from right (bit 0) to left (bit 7). That is, the least significant bit (20) is on the right and most significant bit (27) is on the left.
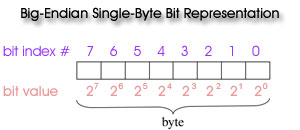
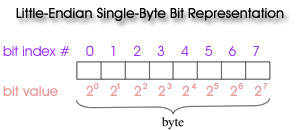
Numerical Whole-Byte Dumps
If you use ncdump or other tools to dump full-byte values (numbers from 0 to 255) from the bit string arrays (SDS's); you can recreate the bit flags using either the Big or Little Endian convention. One simply converts the numbers to 8 bit registers of 0 or 1 where the first bit (bit 0) is the lowest order (least significant) bit (20) and the last bit (bit 7) is the highest order (most significant) bit (27). One then queries groups of sequential bits (matching the length of each flag) in the proper bit order from 0 to 7 and interprets the value of those bits (using the same least significant to most significant convention) to obtain the correct flag value.
Example Interpreting the Cloud_Mask SDS (1st byte only!)
The first byte of the (commonly used) Cloud_Mask SDS is made up of the following 6 flags. (For complete documentation of the Cloud_Mask SDS, see Cloud Mask: Format & Content).
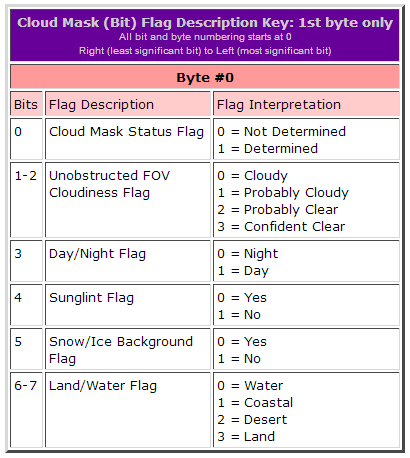
Suppose the following flags were set:
-
Cloud Mask Status = 1 (Determined)
-
Unobstructed FOV Cloudiness = 2 (Probably Clear)
-
Day/Night Path = 0 (Night)
-
Sunglint Path = 1 (No)
-
Snow/Ice Background Path = 1 (No)
-
Land/Water Path = 3 (Land)
Bit-String Dump
Stripping the bits using a bit manipulation tool would yield the following results. Flags are then counted from the right (Big Endian Convention), and least to most significant bits are ordered from right to left for each flag.
Numerical Whole-Byte Dump
However if one uses ncdump or another tool to dump the full-byte numeric value from the array, one gets a byte value of 245. One can then recreate the individual bit flags using either the Big or Little Endian convention, as long as one starts counting the bits (and assigning flags) from the least significant to the most significant bit.
